The XMatch Algorithm
The cross-matching algorithm is the heart of the SkyQuery distributed
query engine. It is absolutely
critical to the success of SkyQuery as a distributed astronomical query service. We have devoted a great deal of thought to the design of this
algorithm, and it is encapsulated in a SQL stored procedure called
spGetMatch that gets
invoked by the XMatch() function of the SkyNode in the C# implementation.
We discuss below the
cross-matching strategy that we adopted and the reasons for adopting it.
Likelihood analysis
The elements of our cross-matching strategy are as follows:
- In order to optimize the network traffic, we first
obtain counts of the number of objects on each database that match the
user-entered constraints that apply to that database.
Also, doing a count brings the objects into the cache.
When we access the objects the second time to do the cross-matching
(see below), hopefully we will just be hitting
the cache, so this will be much faster. Most of the time is spent
in moving objects around between the nodes, so
we don’t want to do it twice.
We require the user to specify the following in
addition to the non-spatial constraints:
The cross-matching algorithm encoded in the
stored procedure is a probabilistic
calculation that minimizes the chisquare parameter as defined by:
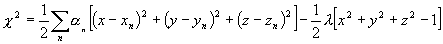
where x,y,z are the Cartesian coordinates corresponding
to the ra and dec specified by the user,
a is a weighting parameter calculated from the
astrometric precision of the survey, and l
is the Langrange multiplier in the minimization to ensure that the
(x,y,z) is a unit vector.
The code for spGetMatch is included in the code listings.
We compute four cumulative quantities at each
cross-identification step – these are
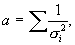 < <
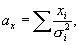
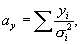
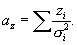
The best position is given by the direction of
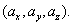 The log-likelihood at that point is given by
The log-likelihood at that point is given by
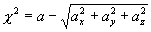
This is
divided by the number of surveys considered up to that point, and compared to
the tolerance. If a tuple’s log-likelihood exceeds this threshold, it is
killed. This cross-identification process is fully symmetric, the particular
order of matching does not matter.
The cross-matching is applied to each node recursively
by the portal when it runs the query execution plan.
Mandatory Matches and Dropouts
The majority of cross-matching queries would search for objects that
match in each one of the selected catalogs.
This is the mandatory match mode meaning that objects must
meet the matching criterion in every archive that the query is run
on. However, users may actually want
those objects that exist in one or more archive(s) and not in the
other(s). These dropouts are often
as important scientifically as the matches, e.g. quasars that appear in an
optical sources catalog but not in a radio sources catalog.
Our algorithm is designed to handle both cases.
The special syntax that we have introduced into ADQL/s to
achieve this is the XMATCH construct, as illustrated in the example below:
SELECT …
FROM SDSS:photoobj p, 2MASS:photoobj t, FIRST:obj r
WHERE XMATCH( p, t, !r ) < 3 AND Region('Circle J2000 0.9 0.8 0.3)
AND (…)
--remaining constraints
which means “find all objects that satisfy the remaining constraints in
the archives represented by
p and t,
but not in the archive represented by
r”. Hence we are selecting mandatory matches in the first
two archives but dropouts in the third.
|
|